

Meta-learning for Mixed Linear Regression
Published at International Conference on Machine Learning (ICML), 2020
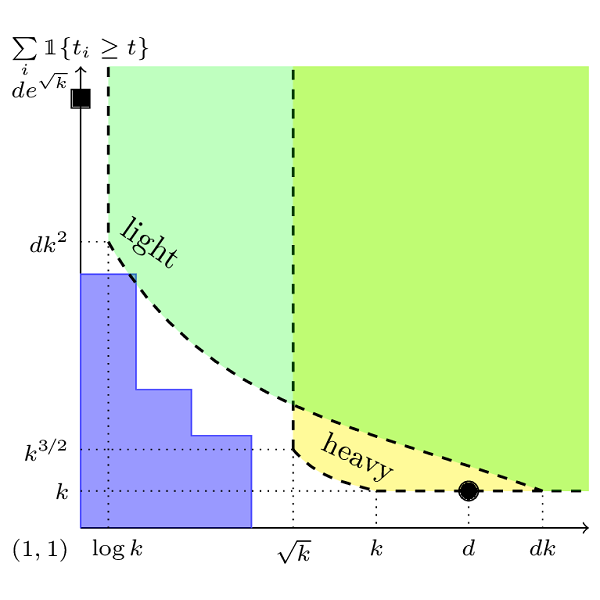
In modern supervised learning, there are a large number of tasks, but many of them are associated with only a small amount of labeled data. These include data from medical image processing and robotic interaction. Even though each individual task cannot be meaningfully trained in isolation, one seeks to meta-learn across the tasks from past experiences by exploiting some similarities. We study a fundamental question of interest: When can abundant tasks with small data compensate for lack of tasks with big data? We focus on a canonical scenario where each task is drawn from a mixture of \(k\) linear regressions, and identify sufficient conditions for such a graceful exchange to hold; The total number of examples necessary with only small data tasks scales similarly as when big data tasks are available. To this end, we introduce a novel spectral approach and show that we can efficiently utilize small data tasks with the help of \(\tilde\Omega(k^{3/2})\) medium data tasks each with \(\tilde\Omega(k^{1/2})\) examples.
The paper has been accepted at the ICML 2020.
Please find the below resources:
Leave a Comment